
In the name of Allah, most gracious and most merciful,
Information is our gateway to knowledge, and skill acquisition. You could think of knowledge as the linkage, and organization of information in our head in a certain way that we could access whenever needed to benefit from it in our different daily activities.
Usually, the Information Retrieval (IR) field is related to search engines in our minds. However, this not the whole story, but just part of it. Even search engines alone are a lot. Imagine how our life will be without search engines like Google for instance. Literally, Search Engines changed the world and helped a lot for transitioning to the information age. Therefore, Information Retrieval has changed the world.
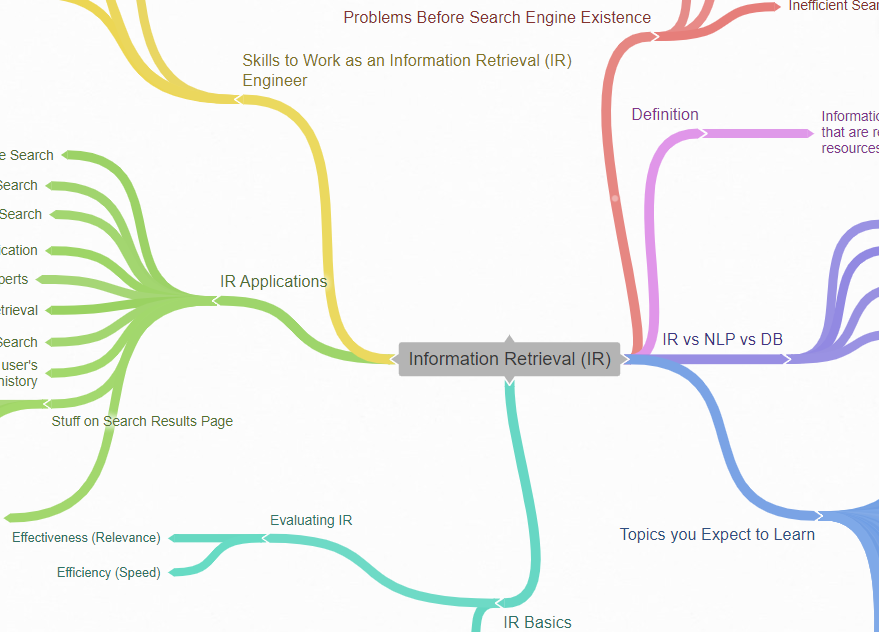
In this post, I will clarify what is Information Retrieval (IR), its relation to Natural Language Processing (NLP), and database (DB), its applications, and some basics about it like, how to evaluate information retrieval models.
Table of Contents
1. Problems Before Search Engine Existence
Before search engines there were two big problems for getting information.:
- Limited Resources: Resources are limited to your specific libraries or databases from which you could access information.
- Ineffective Search (Low Quality): How would you search for what you want in all of these resources? In other words, what are the most relevant resources to search in to find the piece of information you are searching for?
- Inefficient Search (Slow): How much time would you take to search through your resources?
2. Definition
Information Retrieval (IR) is obtaining information resources that are relevant to an information need from a collection of resources.
In simple words, Information Retrieval is about connecting people to information. When I say information, I don’t mean text information but it is whatever thing you are searching for extending to images, audios, and even if you are searching for a human then this is information.
3. Information Retrieval (IR) vs Natural Language Processing (NLP) vs Machine Learning (ML) vs Database (DB)
3.1 Database (DB) vs Information Retrieval (IR)
- Data we search in: Database contains structured data while Information Retrieval mostly deals with unstructured data, or you could even see semi-structured data (like XML files).
- Query Used: In database when we search using SQL for instance, we use well-defined orders like “extract from the third row in this excel file the number of students within a certain age range”. So it is much simpler than IR where the user writes free text, and the search engine searches in a huge amount of unstructured data of many different types.
- Results: In database, we get exact results which are retrieved from structured data while in IR results could be satisfy the user’s needs partially with a certain percentage for instance. Therefore it is not as precise therefore we need a method for evaluating the effectiveness of the search or how much our search results satisfy the user’s information need.
- User-System Interaction: In database, there is no interaction since the user just types what he specifically needs in one-shot queries. However, in IR there is a great interaction because the user could get unrelated results so he keeps changing his queries until getting the results he wants or something even close. Not only this, but the user’s information need could change as well. He could see results that are related in some way to what he is searching for which made him think of something new about his information need. So interactivity is high in IR.
3.2 Natural Language Processing (NLP) vs Information Retrieval (IR)
Natural Language Processing is concerned with processing the human language using different processing techniques, then applying machine learning on the language to build applications like chatbots, machine translation, and sentiment analysis. However, Information Retrieval (IR) is connecting the user to information. Therefore, they are different fields, but they have relations to each other so that they could be used together in some applications. We could use some NLP techniques for reaching the relevant documents so NLP is useful for IR. Also, IR is useful for NLP in some applications like question-answering where we want to retrieve specific parts of the text which probably include answers to questions so I am retrieving information.
IR makes NLP useful. NLP makes IR interesting.
Jimmy Lin
By the way both NLP, and IR are subfields of Artificial Intelligence (AI) while Database (DB) isn’t an AI subfield.
4. Topics you Expect to Learn – (Introduction to Information Retrieval Table of Contents)
- Boolean retrieval
- The term vocabulary and postings lists
- Dictionaries and tolerant retrieval
- Index construction
- Index compression
- Scoring, term weighting, and the vector space model
- Computing scores in a complete search system
- Evaluation in information retrieval
- Relevance feedback and query expansion
- XML retrieval
- Probabilistic information retrieval
- Language models for information retrieval
- Text classification and Naive Bayes
- Vector space classification
- Support vector machines and machine learning on documents
- Flat clustering
- Hierarchical clustering
- Matrix decompositions and latent semantic indexing
- Web search basics
- Web crawling and indexes
- Link analysis
4. IR Basics
4.1 Main Components
There are three main components to IR:
4.1.1 Documents or Collections
The resource you are searching in for information which includes any kind of information; text, images, audios, even people, and so on… This means that they could be unstructured which means that there is no clear structure to information organization in the document like videos (when the speaker will talk) which unlike excel files that are organized in rows, and columns.
4.1.2 Queries
What you write in the search box like what you write in Google search for example.
Query Vs Information Need
There is an important distinction here between query and information need. Information need is what you exactly need, what you are thinking of, it is in your mind. But then you transform this information need into a piece of text for instance that is a representation of your information need. So it is just a representation that is somehow subjective. You know even in language, you could tell someone something to convey a certain concept but when he doesn’t quite catch it, he would ask for more clarification which means that your representation of the concept wasn’t clear enough for him. That what happens between us humans, but what could happen with computers? Possible confusion could even be more challenging which is one of the IR challenges.
A query is a representation of information need. An Information need could be represented in different forms (different queries), and one query could represent many information needs.
One of IR challenges
Different Forms of Queries
Query doesn’t only mean the text you type in Google search, but you could also drag an image into Google Image search. So here are some of the different forms of queries:
- Search by text
- Search by image
- Search by voice or by an audio file
- Search history is a query in recommendation systems which is one of IR applications
- Searching by weighted text by giving different weights to different words in your keyword text search something in the sense of
0.1xkeyword1 + 0.3xkeyword2 + 0.6xkeyword3so here this means that keyword3 is the most important keyword in my query but this advanced search.
4.1.3 Relevant Documents
Documents containing the information that you need, which are the results of your search like Google search results including images, snippets or summaries under each search result, and so on.
4.2 Evaluating IR
Evaluation is key to most if not all engineering fields as far as I know. If you couldn’t evaluate it, how will you improve it. Therefore in IR, there are two key evaluation metrics effectiveness, and efficiency.
4.2.1 Effectiveness (Relevance)
Generally effectiveness means doing the right things, so in information retrieval it is retrieving relevant documents, and here where the term relevance appears.
Relevance is a relation between information need, and documents. In other words, do the documents satisfy the information need I have or not? And here comes something that is very critical which is mapping concepts to queries, and documents.
To clarify thing a little bit more, let me share with you a certain perspective:
- I have mentioned that a query is just a representation to information need, and this representation is somehow subjective. But the information need itself could be seen as something in your head or some concept that you want to represent in query. So here we have a concept as the main building unit of information need.
- But what are documents? Documents could also be seen as a representation of some concept. For example, in this post is considered a document which contains text through which I want to deliver some concepts. So concept is again the building unit of documents.
By this kind of analysis, we could deduce that by information retrieval we are matching or mapping concepts, and that is a real challenge. How to map concepts under the hood between the collection of documents, and the queries?
Example of one of the IR challenges
Here we could see a clear relation between Information Retrieval, and the natural languages when I am talking about text documents. Since natural language doesn’t have a clear structure like computer languages, they include synonyms and require human knowledge. Here comes the knowledge representation problem, which means that to understand the language you need to have some knowledge to deduce the language meaning in different contexts. Context is very important.
For example:
- “I couldn’t enter the couch from the door because it was too big”. It here refers to the couch.
- “I couldn’t enter the couch from the door because it was too narrow”. It here refers to the door.
The same word in the same position, but means different things. So, definitely, you have some knowledge in your mind that says that big things couldn’t fit into small things which helped you understand what it refers to from the context. That is called co-reference resolution in Natural Language Processing.
4.2.2 Efficiency (Speed)
Efficiency generally means doing things with the least amount of wasted time, money, and effort. In other words, the performance of the system. In programming in general, efficiency is related to increasing the code speed (reducing time complexity). What if you typed some query in google, and the results came to you 1 minute later, even 15 seconds later. Well, that will be too high for what we expect, and what we are accustomed to. We are used to getting search results in a fraction of a second so that we even notice no time.
Reducing time complexity means using algorithms that are fast. Usually, in programming, there is a tradeoff between time, and space complexity (the size of the code in memory). So if you want to increase the speed you could do that at the expense of using more memory, and if you want to save memory you could have a slower code. At the end of the day, time in information retrieval is very expensive since users expect to get their results almost instantly.
5. IR Applications
- Enterprise Search
- Social Search
- Microblog Search
- Text Classification
- Expert Search: Searching for human experts
- Speech Retrieval
- Conversational Search
- Recommendation Systems: The query could be the user’s history
- Stuff on Search Results Page
- Snippet selection / summarization
- Categorization (Search Verticals)
- Sponsored Search
- Information Visualization: How to present information in an appealing way
6. Skills required to work as an Information Retrieval (IR) Engineer
Since there is an intersection between IR, NLP, and Machine Learning (ML), you are expected to learn some of the skills required for NLP, and ML engineers, but not necessarily all of them. You could refer to the skills section in those posts where I talked about NLP and Machine Learning.
In addition to those skills, there are skills specifically required for IR engineers. I obtained the following skills from a Senior Information Retrieval Engineer vacancy that I linked to in the references section. Of course, this is not an exhaustive list of the skills but it could be just part of the required skills.
- Software development experience including experience with information retrieval technologies and frameworks like (Elasticsearch, Lucene).
- Familiarity with machine learning algorithms, time series analysis, and anomaly detection algorithms.
- Hands-on experience in Machine Learning, Information Retrieval, Data Mining, Natural Language Processing.
- Experience with Cloud Deployments and Configuration Management.
Thanks
I want to thank a lot, Dr. Tamer Elsayed, for teaching me about this great Information Retrieval (IR) field in the online IR course I have attended with him. If this post was clear and understandable, it was mostly because of the clear way Dr. Tamer represented it in that course. This course’s first lecture from which most of this post content is from is the first link in the references section. Moreover, all this course should be uploaded to Youtube soon in this playlist.
Finally
Thank you. I hope this post has been beneficial to you. I would appreciate any comments if anyone needed more clarifications or if anyone has seen something wrong in what I have written in order to modify it, and I would also appreciate any possible enhancements or suggestions. We are humans, and errors are expected from us, but we could also minimize those errors by learning from our mistakes and by seeking to improve what we do.
Allah bless our master Muhammad and his family.
References
https://www.youtube.com/watch?v=LNK51UbY5BA
https://github.com/telsayed/IR-in-Arabic/tree/master/Summer2021/lectures/day1
https://en.wikipedia.org/wiki/Information_retrieval
https://squirro.com/careers/senior-information-retrieval-engineer/